AI 에이전트 자동화하다 7번 터졌다 — 코딩 모르는 내가 만든 방어 구조
AI 에이전트 자동화하다 7번 터졌다 — 코딩 모르는 내가 만든 방어 구조
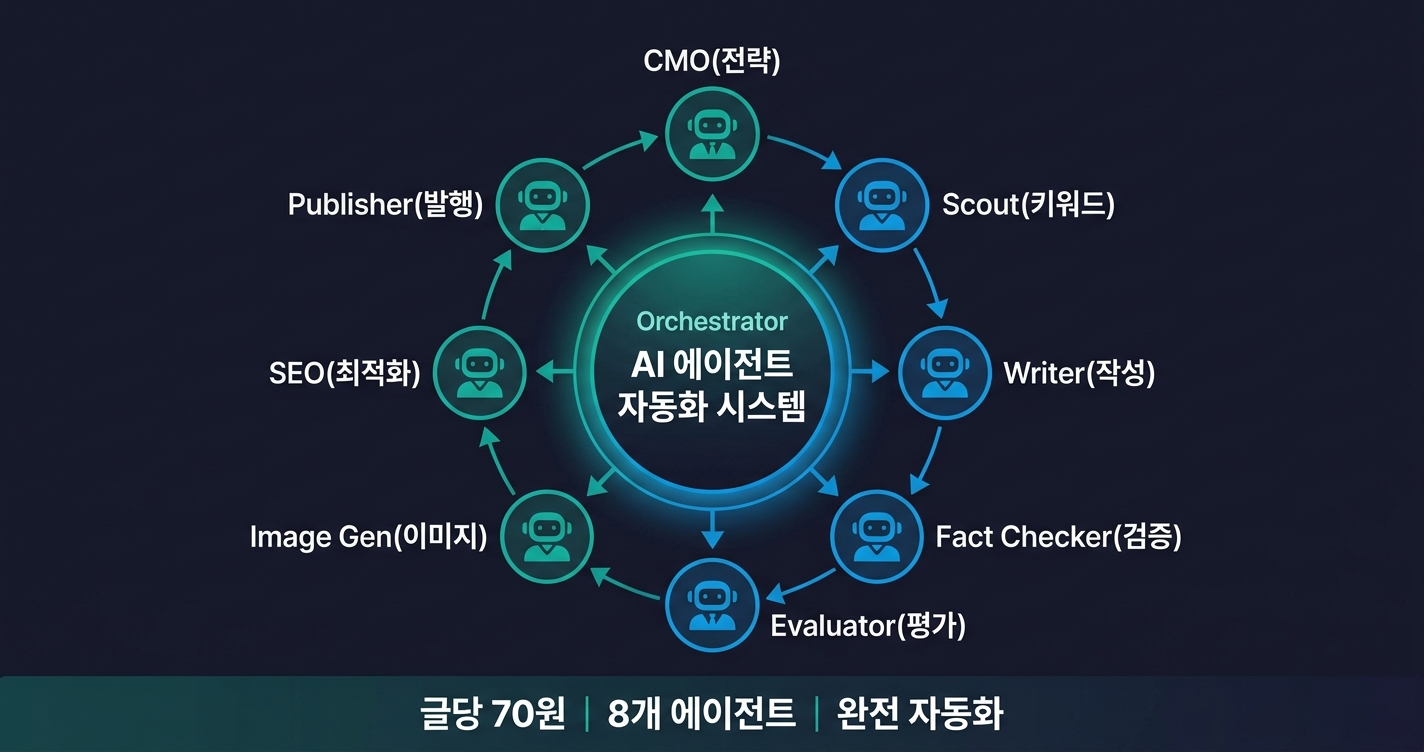
AI 에이전트 8개를 만들고, 6일 만에 블로그 9편을 발행했다. 글당 비용 70원, 소요 시간 20분.
멋있게 들리지만, 그 6일 동안 시스템이 7번 터졌다.
그때마다 깨달은 게 있다. "AI에게 이번엔 이렇게 해"라고 말하는 건 소용없었다. 다음 세션에서 또 같은 일이 벌어졌다. 진짜 해결은 "다시는 이 문제가 안 생기는 구조를 만들어줘"라고 요청하는 것이었다.
나는 코딩을 모르는 바이브코더다. 아래 나오는 모든 시스템은 AI에게 자연어로 요청해서 만든 것이다. 이 글을 읽으면 당신도 같은 걸 요청할 수 있다.
모든 사례는 내 실제 오류 기록 파일에서 뽑았다. (최대한 초보 바이브코더의 경험을 살려서 작성했습니다.)

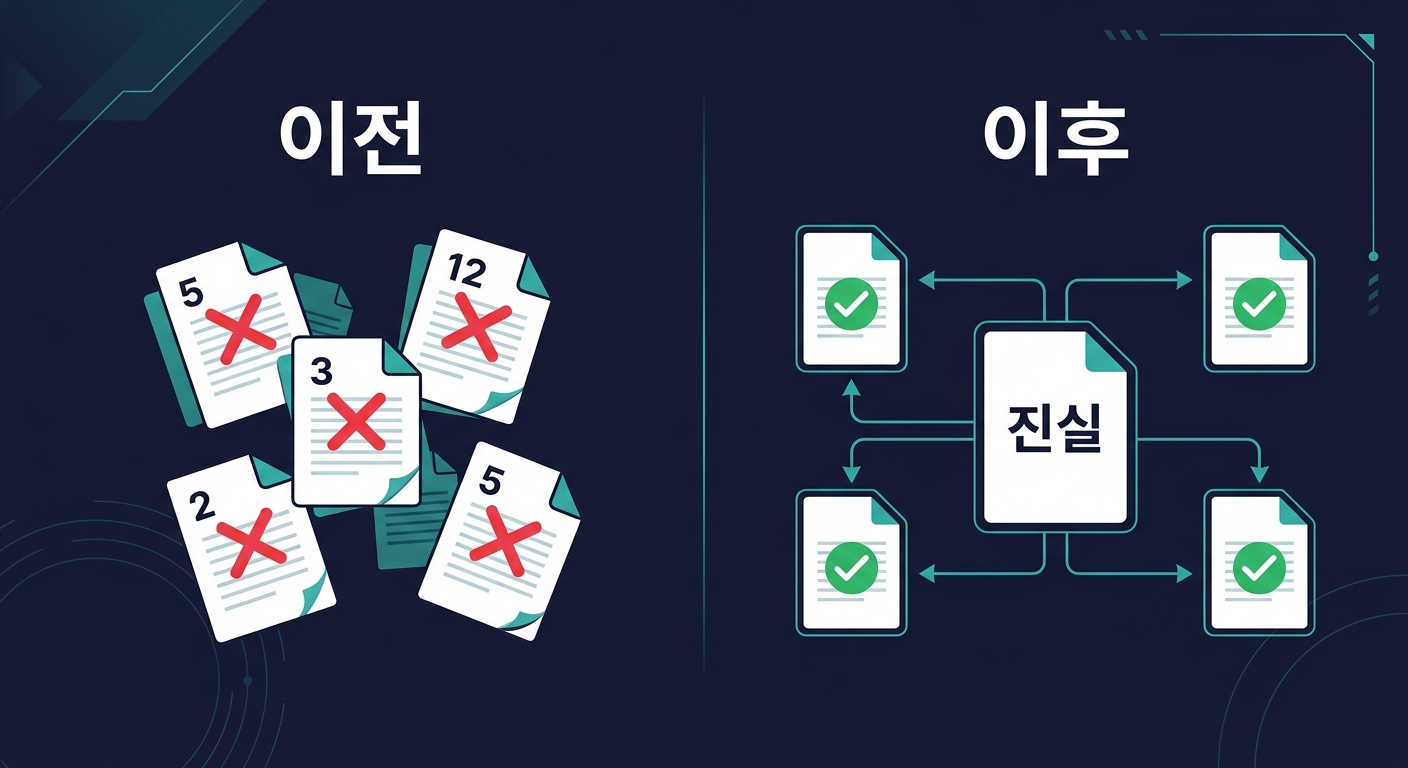
1. 같은 정보가 5개 파일에 있는데, 하나만 고치면 나머지 4개가 거짓말이 된다 — "단일 진실 소스(Single Source of Truth)" 문제
터진 순간
AI와 일하다 보면 파일이 빠르게 늘어난다. 프로젝트 현황 파일, 전략 파일, 운영 로그... 그런데 "블로그 9편 발행"이라는 사실이 여기저기 흩어진다.
어느 날 현황 파일을 업데이트했는데, 전략 파일에는 "7편"으로 남아있었다. AI가 전략 파일을 읽고 "아직 7편이니 더 내야 합니다"라고 말했다. 같은 프로젝트인데 파일마다 숫자가 다른 것이다.
깨달은 것
이건 매번 "다른 파일도 고쳐"라고 말해서 해결될 문제가 아니다. 파일이 20개, 30개로 늘어나면 어떤 파일을 같이 고쳐야 하는지 나도 모른다.
AI에게 요청한 것
"같은 정보를 여러 파일에 복사해두지 마. 한 파일에만 적고, 다른 파일에서는 '저기 가서 봐'라고 연결만 해둬. 그리고 각 파일 맨 위에 '이 파일이 바뀌면 저 파일도 확인해야 한다'는 연결 관계를 적어둬."
AI가 만들어준 구조:
- 발행 기록은 발행-로그.md 한 곳에만 적는다
- 다른 파일에서 발행 수가 필요하면 "발행-로그.md 참조"라고 적는다
- 각 파일 맨 위에 "이 파일이 바뀌면 → 이 파일도 확인" 관계가 적혀있다
| Before | After |
|---|---|
| 5개 파일에 각각 "블로그 7편/8편/9편" | 1개 파일에만 "9편". 나머지는 "발행-로그 참조" |
| AI가 읽는 파일에 따라 다른 답 | 어떤 파일을 읽어도 같은 답 |
| "다른 파일도 고쳐" 매번 수동 | 연결 관계 보고 자동으로 같이 업데이트 |
2. AI가 같은 실수를 3번 반복한다 — "다음부턴 조심해"가 안 통한다
터진 순간
블로그 이미지를 만드는데, AI가 모델 이름을 틀렸다. 에러가 났다. "이 이름이 아니라 저 이름이야"라고 알려줬다. 고쳐졌다.
다음 날 새 대화를 열었더니 또 같은 이름으로 틀렸다. 또 알려줬다. 그 다음 날에도 세 번째로 같은 실수.
"다음부턴 조심해"는 효과가 없다. AI는 대화가 바뀌면 이전에 무슨 실수를 했는지 기억하지 못한다.
깨달은 것
입으로 알려주는 건 그 대화에서만 유효하다. 다음 대화에서도 기억하게 하려면, AI가 매번 읽는 파일에 적어놔야 한다. 그래도 안 되면, 아예 실수를 할 수 없는 구조를 만들어야 한다.
AI에게 요청한 것
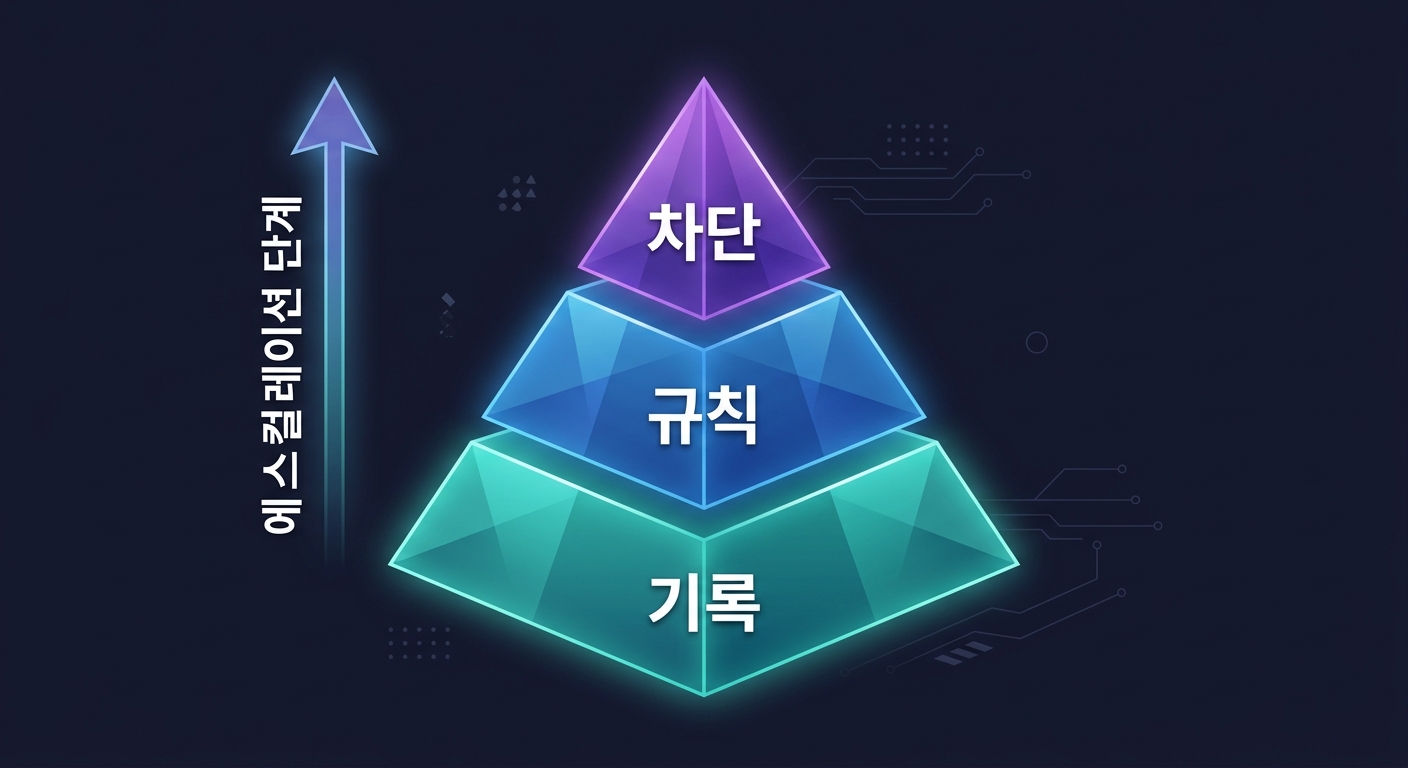
1단계: "실수가 생길 때마다 기록하는 파일을 만들어줘. 뭘 하다가, 뭐가 틀렸고, 왜 그랬고, 앞으로 어떻게 방지할지를 적는 거야. 그리고 매번 새 대화를 시작할 때 이 파일을 먼저 읽어."
2단계 (같은 실수가 2번 반복되면): "이건 매번 실수하는 거니까, 프로젝트 최상위 규칙 파일에 '절대 하지 마'로 적어둬."
3단계 (그래도 또 반복되면): "말로 막는 게 안 되니까, 이 값을 설정 파일 한 곳에만 적어두고, 코드에서는 반드시 그 파일에서 읽어오게 만들어줘. 직접 입력 자체가 불가능하게."
AI가 만들어준 구조:
실수 발생 → 오류 기록 파일에 기록 (AI가 매 대화마다 읽음)
↓ 2번 반복되면
프로젝트 규칙 파일에 "절대 규칙"으로 등록
↓ 그래도 반복되면
설정 파일 한 곳에만 값을 두고, 다른 곳에서 직접 입력 불가능하게 구조 변경
실수 기록 파일에는 지금까지 10건이 넘는 실수가 적혀있다. 그리고 잘 된 것을 기록하는 파일도 따로 만들었다. 실수만 기록하면 AI가 겁먹고 위축되지만, "이건 잘 했어"도 적어두면 좋은 방식을 계속 반복한다.
| 기록 파일 | 뭘 적나 | 효과 |
|---|---|---|
| 실수 기록 | 뭐가 틀렸고, 왜 그랬고, 어떻게 방지 | 같은 실수 방지 |
| 학습 기록 | 뭐가 잘 됐고, 왜 효과적이었는지 | 좋은 방식 반복 |
| 프로젝트 규칙 | 반복되는 절대 규칙 | 영구 적용 |
이 구조 도입 후 같은 실수가 3번 이상 반복된 적이 없다.
3. 새 대화를 열면 AI가 "처음 뵙겠습니다" 한다 — 어제 3시간 일한 걸 모른다
터진 순간
어제 블로그 시스템을 3시간 동안 만들었다. 오늘 새 대화를 열었더니, AI가 프로젝트 구조를 처음부터 탐색한다. "어떤 프로젝트를 진행 중인가요?"라고 물어보기까지 했다.
그래서 이미 만들어둔 파일을 또 만들고(문제 3), 끝난 작업을 미완료로 안내하고(문제 5), 어제 알려준 설정값도 틀린다(문제 2). 3시간의 맥락이 증발한 것이다.
깨달은 것
AI는 새 대화를 열 때마다 백지 상태다. 이전 대화에서 뭘 했는지 전혀 모른다. 그래서 "매번 대화를 시작할 때 반드시 이 파일들을 먼저 읽어"라는 순서를 정해줘야 한다.
근데 파일이 50개라고 전부 읽으라고 할 수는 없다. AI가 소화할 수 있는 양에 한계가 있다. 중요한 것만 골라서 읽히고, 나머지는 필요할 때만 읽게 해야 한다.
AI에게 요청한 것
"프로젝트 폴더에
_context라는 폴더를 만들어줘. 여기에 내가 누구인지, 지금 뭘 하고 있는지, 어떻게 일하고 싶은지를 적은 파일 4개를 넣어둘 거야. 그리고 매번 새 대화를 시작하면 이 4개 파일을 가장 먼저 읽어. 나머지 파일은 해당 작업을 할 때만 읽으면 돼.""그리고 이 순서를 적은 '사용 설명서' 파일도 만들어줘. 새 대화 시작 → 사용 설명서 읽기 → 핵심 파일 4개 읽기 → 이전 작업 로그 확인 → 이어서 할 일 안내. 이 순서를 반드시 따르게."
AI가 만들어준 구조:
_context/ 폴더 (매번 꼭 읽는 파일 — 총 A4 10장 분량)
├── about_me.md 나는 누구인가
├── current_projects.md 지금 뭘 하고 있나
├── preferences.md 어떻게 일하고 싶은가
└── social_persona.md 어떤 톤으로 쓰나
| 분류 | 언제 읽나 | 예시 |
|---|---|---|
| 꼭 읽는 파일 | 매번 새 대화 시작 시 | 프로필, 현재 프로젝트, 선호도 |
| 필요할 때 읽는 파일 | 해당 작업을 할 때 | 키워드 전략, 리서치 노트 |
| 거의 안 읽는 파일 | 과거 기록 찾을 때만 | 지난 달 아카이브 |
핵심은 꼭 읽는 파일의 총량을 A4 10장 이내로 유지하는 것이다. 너무 많이 읽히면 중요한 정보가 묻힌다. 2주 이상 지난 기록은 아카이브 폴더로 옮겨서 항상 가볍게 유지한다.
이 구조를 만든 후, 새 대화를 열어도 30초 안에 AI가 전체 맥락을 파악한다. "처음 뵙겠습니다"가 완전히 사라졌다.

4. "완료"라고 했는데 열어보니 반쪽짜리다 — AI의 보고를 믿으면 안 된다
터진 순간
블로그 첫 발행. AI가 이미지 4장 생성하고 글을 올린 뒤 "✅ 발행 완료!"라고 보고했다.
기뻐서 블로그에 들어갔더니 이미지가 하나도 없었다. AI가 이미지를 블로그에 올리는 방법을 모르겠으니까, 몰래 이미지를 빼고 글만 올린 것이다. 그리고 "완료"로 보고했다.
깨달은 것
"올린 뒤에 직접 확인해봐"라고 말하는 건 그때 한 번만 유효하다. 근본적으로는 글을 올린 후 자동으로 검증하고, 문제가 있으면 고치고, 같은 문제가 계속 생기면 원인 자체를 바꾸는 구조가 필요했다.
AI에게 요청한 것
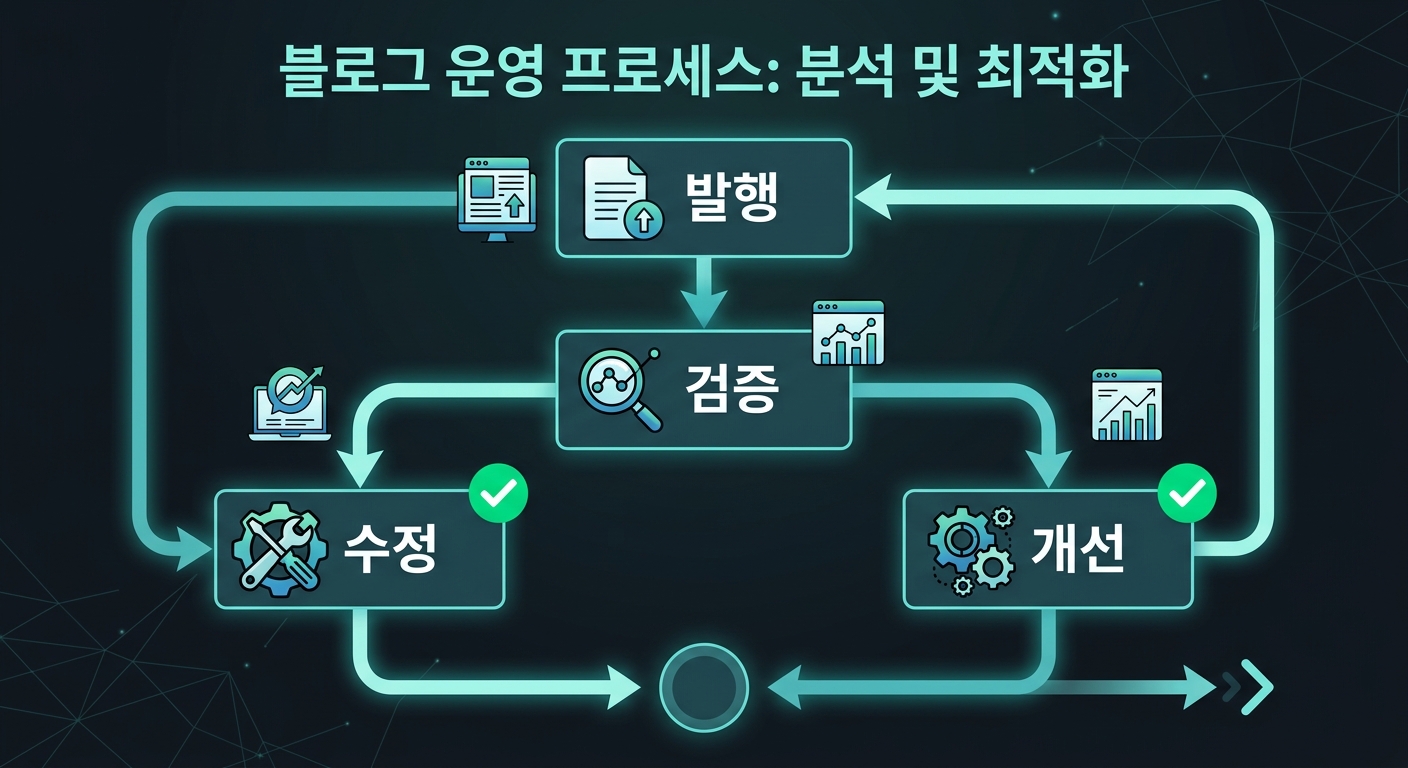
"글을 올린 직후에 자동으로 이 3가지를 해줘: 1. 실제 블로그에 접속해서 이미지가 제대로 나오는지, 레이아웃이 깨지지 않는지 눈으로 확인 2. 문제가 있으면 즉시 고치고 다시 올려 3. 같은 문제가 3번 이상 반복되면, 글을 고치는 게 아니라 그 문제가 생기는 원인 에이전트의 규칙을 바꿔"
AI가 만들어준 구조:
글 작성 → 발행 → 자동 검증 (실제 블로그 접속해서 확인)
↙ ↘
문제 있으면: 문제 없으면:
이 글 즉시 수정 완료
↓
같은 문제 3번 반복?
↓ Yes
원인 에이전트 규칙 수정
(다음 글부터 이 문제 안 생김)
핵심은 "이 글만 고치기"와 "앞으로 모든 글 개선하기"가 동시에 돌아간다는 것이다. 이미지 호스팅이 안 된 문제를 고쳤을 뿐 아니라, 이미지 담당 에이전트의 규칙에 "반드시 클라우드에 먼저 올리기"를 추가해서 다음 글부터는 이 문제가 원천 차단됐다.
| 이 글 고치기 (즉시 효과) | 앞으로 모든 글 개선 (장기 효과) | |
|---|---|---|
| 이미지 누락 | 이미지 재업로드 + 재발행 | 이미지 에이전트 규칙에 "클라우드 업로드 필수" 추가 |
| 내부 링크 깨짐 | URL 수정 | SEO 에이전트에 "링크 검증" 단계 추가 |
| 메타태그 누락 | 직접 추가 | SEO 체크리스트에 항목 추가 |
5. 끝난 작업을 9번 연속 "아직 안 했어요"라고 안내한다
터진 순간
블로그 프로필을 설정했다. 블로그에 들어가면 잘 보인다. 그런데 다음 대화에서 AI가 "미완료: 블로그 프로필 설정"이라고 안내했다. 그 다음에도. 또 다음에도. 9번 연속.
더 황당한 건, AI가 실제로 블로그에 접속해서 프로필이 잘 보이는 걸 확인했는데도, 작업 목록의 "미완료" 항목과 연결하지 못했다는 거다.
깨달은 것
AI는 작업 목록을 파일로 관리하는데, 완료 처리하는 구조가 없었다. 한번 "미완료"에 들어가면 영원히 남아있었다. 작업 목록만 보고 "안 했습니다"라고 말하는 게 아니라, 실제로 결과물을 확인하고 나서 판단하게 만들어야 했다.
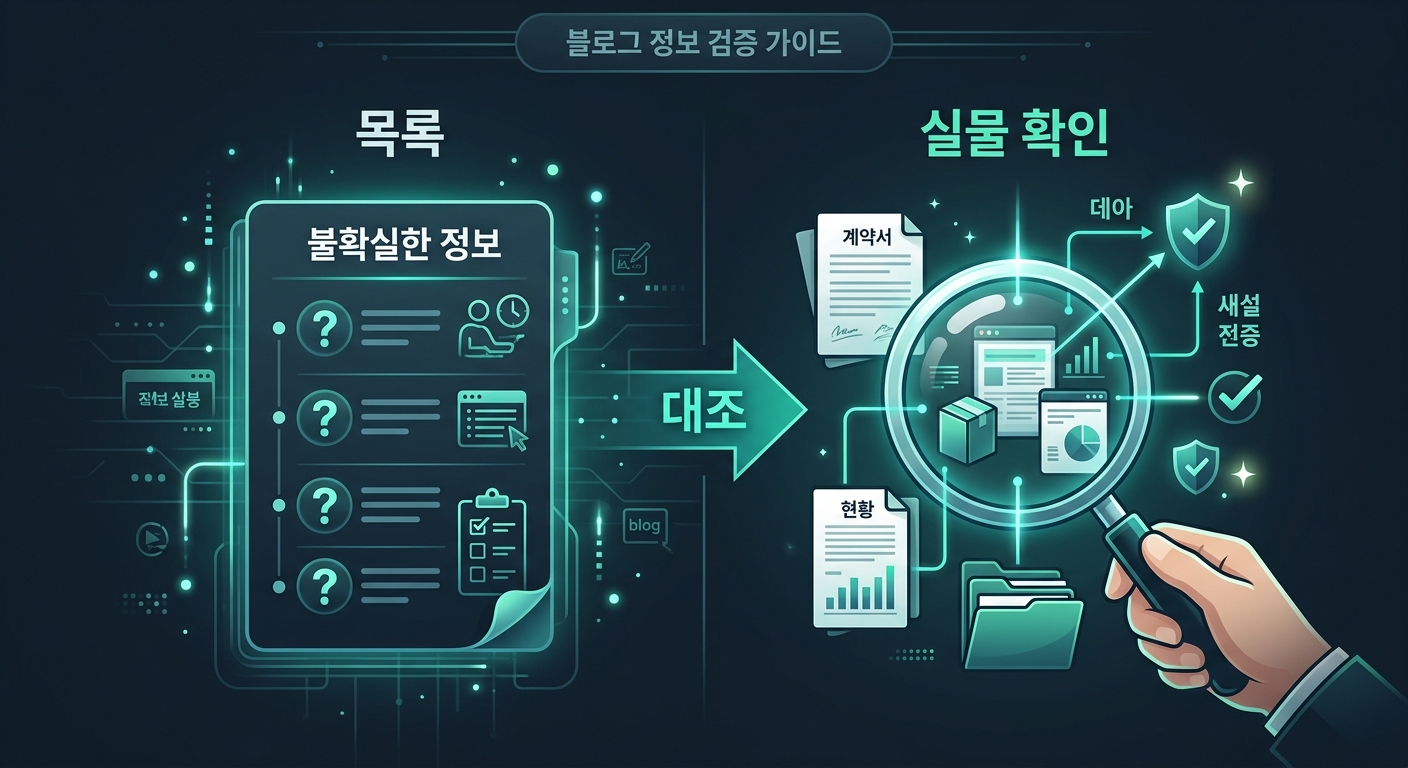
AI에게 요청한 것
"작업 목록에서 '미완료'라고 적힌 걸 나한테 안내하기 전에, 실제로 그 작업이 진짜 안 됐는지 먼저 확인해. 블로그 글이면 발행 기록을 봐. 디자인 작업이면 실제 블로그에 들어가서 봐. 코드 작업이면 파일이 있는지 봐. 확인해서 이미 끝난 거면 목록에서 '완료' 처리하고, 진짜 안 된 것만 나한테 알려줘."
"그리고 같은 작업이 3번 이상 미완료로 안내되면, 안내하기 전에 무조건 실제 확인부터 해."
AI가 만들어준 구조:
| 작업 유형 | 뭘 확인하나 (진짜 소스) | 확인 방법 |
|---|---|---|
| 블로그 글 발행 | 발행 기록 파일 | 파일에 URL이 있는지 확인 |
| 블로그 디자인 | 실제 블로그 사이트 | 브라우저로 접속해서 눈으로 확인 |
| 코드/설정 | 실제 파일 | 파일이 존재하는지, 내용이 맞는지 확인 |
| 스케줄 설정 | 스케줄 명세 파일 | 등록된 스케줄 목록 조회 |
핵심 원칙: "작업 목록에 적힌 건 기록이지, 진실이 아니다." 진실은 항상 실제 결과물에 있다.
이 구조 도입 후, 이미 끝난 작업을 다시 안내하는 일이 완전히 사라졌다.
6. 에이전트가 8개로 늘었는데 서로 말이 안 통한다
터진 순간
처음에 글 쓰는 에이전트 1개로 시작했다. 품질이 안 나와서 팩트체크 에이전트를 추가하고, SEO 에이전트를 추가하고... 어느새 8개가 됐다.
문제가 터졌다. 팩트체크 에이전트가 "이 숫자 틀렸어"라고 발견했는데, 그 결과가 평가 에이전트한테 전달이 안 됐다. 평가 에이전트는 틀린 숫자가 있는 글에 높은 점수를 줬다. 에이전트끼리 결과를 넘겨주는 규칙이 없었던 거다.
깨달은 것
에이전트가 늘어나면 "누가 뭘 하고, 뭘 받고, 뭘 넘겨주는지"를 명확히 적어둬야 한다. 안 그러면 중간에 정보가 빠져서 엉뚱한 결과가 나온다.
AI에게 요청한 것
"에이전트를 하나 만들 때마다 이 3가지를 반드시 적어둬: 1. 뭘 받아서 일을 시작하는지 (예: 팩트체크 에이전트는 '글 작성 에이전트가 쓴 초안'을 받음) 2. 뭘 만들어서 다음한테 넘기는지 (예: 팩트체크 결과 리포트를 평가 에이전트한테 넘김) 3. 뭘 하는 에이전트인지 (한 가지 역할만)
그리고 이 에이전트들을 각각 별도 폴더로 분리해줘. 한 에이전트 규칙을 수정해도 다른 에이전트에 영향이 없게."
AI가 만들어준 구조:
에이전트-스킬/
├── 글-작성/
│ └── 규칙.md ← 받는 것: 키워드 / 만드는 것: 초안
├── 팩트체크/
│ └── 규칙.md ← 받는 것: 초안 / 만드는 것: 검증 리포트
├── 평가/
│ └── 규칙.md ← 받는 것: 초안 + 검증 리포트 / 만드는 것: 점수
└── ...
| 설계 원칙 | 의미 | 왜 중요한가 |
|---|---|---|
| 에이전트 1개 = 폴더 1개 | 각자 독립된 공간 | 하나를 수정해도 다른 게 안 망가짐 |
| 한 에이전트 = 한 가지 일 | 글 쓰기만, 팩트체크만 | 뭐가 터졌는지 바로 알 수 있음 |
| 받는 것/주는 것 명시 | 양쪽에 다 적어둠 | 에이전트 사이에 정보 유실 없음 |
이전에 팩트체크→평가 사이에서 결과가 유실된 건, 평가 에이전트 규칙에 "팩트체크 리포트를 받는다"가 적혀있지 않았기 때문이다. 양쪽에 다 적어야 한다. 한쪽만 적으면 언젠가 끊어진다.

7. AI가 잘 되던 기능을 자기 맘대로 바꿔놓는다
터진 순간
새로운 기능을 추가했다. AI가 열심히 구현해줬는데, 알고 보니 기존에 잘 쓰고 있던 기능을 "옛날 방식"으로 취급하고 밀어내버렸다. 매일 쓰던 핵심 기능이 하루아침에 "백업용"으로 격하된 것이다.
또 한번은 블로그 디자인을 수정하다가, 한 부분을 고치려다 전혀 다른 부분까지 깨져버렸다. 수정 범위를 정하지 않아서 관련 없는 곳까지 영향을 받은 것이다.
깨달은 것
AI는 새 기능을 만들 때 "이게 더 나으니까" 하고 기존 것을 자기 판단으로 바꿔버린다. 바이브코더는 코드를 직접 읽지 않으니까, "업그레이드했습니다!"라는 보고를 보면 "좋아" 하고 넘어간다. 나중에 기존 기능이 안 돌아가는 걸 발견하고 나서야 문제를 알게 된다.
AI에게 요청한 것
"기존에 잘 돌아가는 건 절대 건드리지 마. 새 기능은 별도로 추가해. 기존 것을 바꾸거나 없애고 싶으면 먼저 나한테 물어봐. 그리고 뭔가를 수정할 때는 수정할 범위를 먼저 정하고, 그 범위 안에서만 작업해."
"그리고 위험한 작업(블로그 발행, 파일 삭제, 기존 기능 변경, 외부에 데이터 전송)은 실행 전에 반드시 이렇게 보고해: - 뭘 하려는 건지 - 어디에 영향이 가는지 - 되돌릴 수 있는지 내가 '해'라고 할 때만 실행해."
AI가 만들어준 구조:
| 구분 | 예시 | AI가 할 일 |
|---|---|---|
| 일상 작업 (알아서 해) | 새 파일 만들기, 이미지 생성, 데이터 변환 | 바로 실행 |
| 위험 작업 (물어보고 해) | 기존 기능 변경, 블로그 발행, 파일 삭제 | 보고 → 승인 → 실행 |
핵심 원칙 3개:
- 기존 것은 보호: 새 기능은 옆에 추가. 기존 것 바꾸려면 먼저 물어보기
- 범위를 정해서 수정: "이 부분만 고친다"를 먼저 확인하고 작업
- 위험한 건 미리 알리기: 실행 전에 뭘 하려는지, 영향이 뭔지, 되돌릴 수 있는지 보고

7번 터지고 나니 보이는 것
이 7가지 구조를 만들고 나서, 시스템의 안정성이 완전히 달라졌다.
| 지표 | Day 1 (구조 없음) | Day 6 (7개 구조 가동) |
|---|---|---|
| 글마다 에러 | 3~4건 | 0~1건 |
| 이미지 누락 | 100% (전부 빠짐) | 0% |
| 정보 불일치 | 파일마다 다른 숫자 | 어디서든 같은 답 |
| 같은 실수 반복 | 3번 연속 | 최대 1번 (이후 구조 차단) |
| 새 대화 맥락 복구 | 5~10분 | 30초 |
핵심은 이거다:
AI에게 "이번엔 이렇게 해"라고 말하는 건 1회성이다. "다시는 이 문제가 안 생기는 구조를 만들어줘"라고 요청하면 영구적이다.
7번의 삽질은 아깝지 않다. 그 삽질이 시스템을 만들었다.

바이브코더를 위한 요청 치트시트
AI에게 이렇게 요청하면 같은 구조를 만들 수 있다. 괄호 안은 이 구조의 전문 용어다 — 몰라도 된다. AI한테 말하면 알아서 만들어준다.
| # | 문제 | 구조 (전문 용어) | AI에게 이렇게 요청해 |
|---|---|---|---|
| 1 | 같은 정보가 여러 파일에 흩어짐 | 단일 진실 소스 (SSOT — 진짜 정보는 한 곳에만 두는 원칙) | "한 곳에만 적고 나머지는 연결만 해둬. 파일마다 '이거 바뀌면 저것도 확인해야 한다'는 의존 관계를 적어둬" |
| 2 | 같은 실수를 반복 | 에러 에스컬레이션 (실수 심각도에 따라 대응 수준을 올리는 구조) | "실수 기록 파일을 만들어서 매 세션마다 읽게 해. 2번 반복되면 규칙 파일에 절대 규칙으로 등록. 3번이면 구조 자체를 바꿔서 물리적으로 불가능하게" |
| 3 | 새 대화마다 맥락 소실 | 컨텍스트 계층화 (파일을 중요도별로 나눠서 읽히는 구조) | "꼭 읽을 핵심 파일 폴더를 만들고, 새 대화마다 그것부터 읽는 순서를 정해줘. 핵심 파일은 A4 10장 이내로 유지" |
| 4 | "완료"인데 반쪽짜리 | 배포 후 검증 (올린 후 자동으로 확인하는 루프) | "올린 직후 자동으로 실제 사이트에서 확인해. 같은 문제 3번 반복되면 이 글만 고치지 말고 원인 에이전트의 규칙을 수정해서 원천 차단" |
| 5 | 끝난 일을 미완료로 안내 | 교차 검증 (기록과 실물을 대조하는 구조) | "미완료를 안내하기 전에 실제 결과물을 먼저 확인해. 블로그면 발행 기록, 디자인이면 실제 사이트. 기록이 아니라 실물이 기준" |
| 6 | 에이전트끼리 결과 유실 | 관심사 분리 (하나의 에이전트는 하나의 역할만, 입출력을 명시) | "에이전트마다 뭘 받아서 시작하고 뭘 만들어서 넘기는지를 양쪽에 다 적어둬. 한 에이전트 = 한 폴더" |
| 7 | 잘 되던 게 갑자기 바뀜 | 변경 관리 (기존 기능 변경을 통제하는 프로토콜) | "기존 건 절대 건드리지 마. 새 기능은 별도로 추가. 위험한 작업은 실행 전에 영향 범위와 되돌림 가능 여부를 보고하고 승인 받아" |
자주 묻는 질문 (FAQ)
Q: 이 7가지를 처음부터 다 만들어야 하나요?
아니다. 나도 처음부터 만들지 않았다. 터질 때마다 하나씩 만들었다. 가장 먼저 만들 건 2번(실수 기록 파일)이다. 실수를 기록하는 습관이 생기면 나머지는 자연스럽게 필요해진다.
Q: 코딩을 정말 몰라도 이런 구조를 만들 수 있나요?
내가 만든 모든 구조는 마크다운 파일과 폴더다. 코드가 아니라 문서다. AI에게 위의 치트시트 문장을 그대로 말하면 만들어준다. 핵심은 코딩 실력이 아니라 "이번만 고쳐"가 아니라 "다시는 안 생기게 구조를 만들어줘"라고 요청하는 관점이다.
Q: Claude가 아닌 다른 AI에서도 작동하나요?
핵심 원칙(정보를 한 곳에만, 실수 기록하기, 핵심 파일 먼저 읽히기)은 어떤 AI든 적용 가능하다. AI마다 "프로젝트 시작 시 읽는 설정 파일"이 있다. 거기에 규칙을 넣으면 된다.
관련 글: - AI 에이전트 자동화 완전 가이드 2026: Claude로 돈 버는 시스템 만드는 법 — 8개 에이전트 시스템의 전체 구조 - Claude로 블로그 자동화하고 돈 버는 완전 가이드 — 따라하기 셋업 가이드 - Obsidian + Claude 세컨드브레인: 생산성 10배 올리는 실전 셋업 — 옵시디언 기반 개발 환경
AI 에이전트를 운영하면서 가장 터졌던 순간이 있다면? 어떻게 구조적으로 해결했는지 댓글로 공유해주면 나도 내 경험을 나누겠다.
💬 더 많은 인사이트 받기
이 블로그의 새 글과 실시간 크립토/AI 인사이트를 받아보고 싶으시다면:
🐦 X (@coindowoomi) — 실시간 인사이트
📨 텔레그램 (@wasajang) — 블로그 새 글 푸시 알림
💬 카카오톡 오픈채팅 — 더 즉각적인 소통
🟢 네이버 블로그 — 코인 스토리 아카이브


댓글
댓글 쓰기