코딩 까막눈이 AI에게 글쓰기 시켜 블로그·X·텔레그램·네이버 4채널 공장 차린 한 달
코딩 까막눈이 AI에게 4채널 글 공장 차려줬다
한 달, 약 20편 — 자동화는 쉬웠다. 진짜 어려웠던 건 "AI가 쓴 티"를 지우는 일이었다
2026년 3월 말, AI가 쓴 글 한 편을 블로거 → X(트위터) 셀프리플라이 → 텔레그램 푸시 → 네이버 블로그 축약본까지 자동으로 분배하는 OSMU(원소스멀티유즈) 시스템을 짰다. 약 한달간 다듬었고, 블로거 기준 약 20편을 찍었다. 이 글은 빌더 리포트다. 자랑이 아니라, 어떤 부분에서 문제였고, 왜 그렇게 설계했는지에 대한 기록.

왜 이 글을 쓰는가 — AI OSMU 포스트들의 공통 패턴부터
먼저 솔직하게 말하면, "내가 AI 자동화 시스템을 만들었다"는 포스트는 2025~2026년 X에 차고 넘친다. 그래서 쓰기 전에 최근 12개월 커뮤니티에서 실제 반응 좋았던 OSMU 경험담 10여 개를 딥리서치로 훑었다 (Claude + Gemini Pro + Codex + Grok 4AI 병렬). 공통 패턴은 이랬다.
살아남은 포스트들의 공통 특징
- "AI draft + human polish" 하이브리드 — 완전 자동은 예외 없이 슬롭(slop, 저품질 AI 콘텐츠) 판정받는다.
- Telegram을 승인/편집 허브로 사용 — 한 번의 메시지로 파이프라인 전체 트리거, 자연어 컨펌.
- 품질 게이트 — "70점 이상만 통과", "어미 다양화 규칙", "클리셰 차단 목록" 같은 명시적 필터.
- 1개 고가치 원소스 → 5-6개 포맷 — 무차별 양산(mass gen)이 아니라 선별.
- 수익화 직결 + 꾸준한 볼륨 — AdSense / 쿠팡 / Shorts 수익과 일 2-4회 발행.
반대쪽(AI slop 반박)의 공통 논리
- "AI 글은 어미가 다 똑같아서 바로 티 난다"
- "채널이 많을수록 모두 똑같으면 해가 된다"
- "AI가 기존 콘텐츠까지 재활용하면 originality가 0이다"
HackerNews의 "AI slop thread"는 231점 175댓글로, 독자들은 AI 숨긴 글을 읽다가 멈춘다고 반복해서 증언한다. Merriam-Webster는 2025년 올해의 단어로 "AI slop"을 골랐다.

그래서 이 글의 각도
이 글은 "구축기"가 아니라 "약 20편 돌리고 나서의 현장 리포트"다. 스택은 맨 아래 한 번에 공개하고, 대부분은 "자동화 자체는 AI에게 명령만 잘하고 우회만 하면 대부분 해결되는데, 누구도 읽지 않을 것 같은 글(AI slop)을 어떻게 양산하지 않을 것인가"에 쓴다. 이게 지금 시장에서 먹히는 각도라고 판단했다.
출발점 — 내가 풀려던 문제
2026년 3월의 상태
- 쿠팡 로켓그로스 도전 실패, 중고폰 240대로 만든 채굴기 손절, 바이브코딩도 수차례 실패와 중도 하차... 다 돈 벌고 싶어서 하는 건데 수업료만 내고 있다.
- 유튜브 채널 1일 1영상 돌리는 중 (40일만에 구독자 1,150, 조회 143K).
- X @coindowoomi 616팔로워, 일 답글 20+ / 포스팅 3-5.
- 블로그 AdSense 신청 준비 중. 발행 건수가 필요.
- 옵시디언 볼트에 3년치 리서치·실패담·DeFi 경험담과 새로운 아이디어에 대한 프로젝트들이 쌓여있음.
우선 가장 크게 느꼈던 문제는 하나였다. 어떤 한 SNS 채널에서 유입만 확보해도 크게 성공할 수 있다는데, 나는 너무 게으르고 여러 채널을 활용하는 방법도 모른다. OSMU 하라는데 너무 귀찮다. 3~4채널을 관리하고 포스팅을 옮기는 데에만 하루 3~4시간이 든다. 귀찮아서 그냥 안 했었다. 같은 주제를 블로거용(긴 튜토리얼), X용(훅 1줄+롱폼), 텔레그램용(요약), 네이버용(한국 검색용 축약)으로 각각 고쳐 쓰는 게 말이 안 됐다.

바라던 것
글 하나 쓰면 4채널에 알아서, 그런데 각 채널의 톤과 독자에 맞게, 슬롭 판정 안 받고 나가는 시스템.
완전 자동은 필요 없었다. 필요한 건 "내가 컨펌만 하면 돌아가는 파이프라인". 이게 이번 시스템의 설계 원칙이 된다.
구조 — 어떻게 짰는가
전체 다이어그램 (논리 수준)
[Nucleus 1편]
│
▼
┌───────────┐
│ Orchestrator │ ← 사용자 컨펌 게이트
└───────────┘
│
├──► Blogger Adapter ──► Blogger API ──► 매일 19:00 크론
│ │
│ └──► RSS ──► Telegram 자동 푸시
│
├──► X Adapter ──► 롱폼 1트윗 + 셀프리플라이 (블로그 URL)
│
└──► Naver Adapter ──► 축약본 (Blogger 유입 CTA)
핵심은 Orchestrator가 채널마다 다른 어댑터를 부른다는 것. 같은 글을 그냥 복붙하지 않는다. 각 어댑터는 해당 플랫폼에 맞게 번역한다.

스택
| 레이어 | 선택 | 이유 |
|---|---|---|
| 생성 모델 | Claude (Opus 4.6) + Gemini + Codex | Claude 오케스트레이션, Codex 공격적 검토 시너지, Gemini 2M 컨텍스트로 볼트 전체 맥락 기반 분석 |
| 지식 소스 | 옵시디언 볼트 | "볼트 = 내 두뇌" 프레임. 원소스가 내 경험/리서치여야 AI가 번역할 수 있음 |
| 파이프라인 런타임 | Claude Code 하네스 + 커스텀 스킬 | 8개 블로그 생산 스킬 (keyword-scout → content-writer → fact-checker → evaluator → Codex 독립검수 → image-generator → seo-optimizer → publisher) |
| Blogger 발행 | Python blog_publish.py + GitHub Actions |
매일 19:00 크론, Blogger API v3, 또는 수동 컨펌 즉시 발행. |
| X 자동화 | Twitter API + 커스텀 drafts 큐 | 롱폼 1트윗 형식, 셀프리플라이로 블로그 URL |
| 네이버 발행 | Chrome MCP 반자동 프로토콜 | 네이버는 API가 빡빡해서 브라우저 자동화. 수동 승인 게이트 포함 |
| 텔레그램 푸시 | 블로그 RSS → Telegram 봇 | @wasajang 채널. 블로거 발행 시 자동 트리거 |
| 색인 가속 | Google Search Console Indexing API | Blogger 발행 후 자동 URL 등록 |

핵심 설계 결정 3가지
1. "1 Nucleus → 4 어댑터", 공유 문서 1개가 아님 같은 글을 4곳에 복붙하면 AI slop 쇼핑몰이 된다. Nucleus는 "이 주제의 핵심 주장 + 근거 + 숫자"만 담고, 각 어댑터가 다시 쓴다. - Blogger: 5,000~9,000자, 이미지 9~18장, 에버그린 튜토리얼 톤. - X: 250~500자 롱폼 1트윗, 첫 2-3문장이 훅. 스레드 X. - Telegram: 블로그 제목+3줄 요약+URL 2개. - Naver: 1,500~2,500자 축약본, 본문 60-70% 지점에 Blogger 유입 CTA.
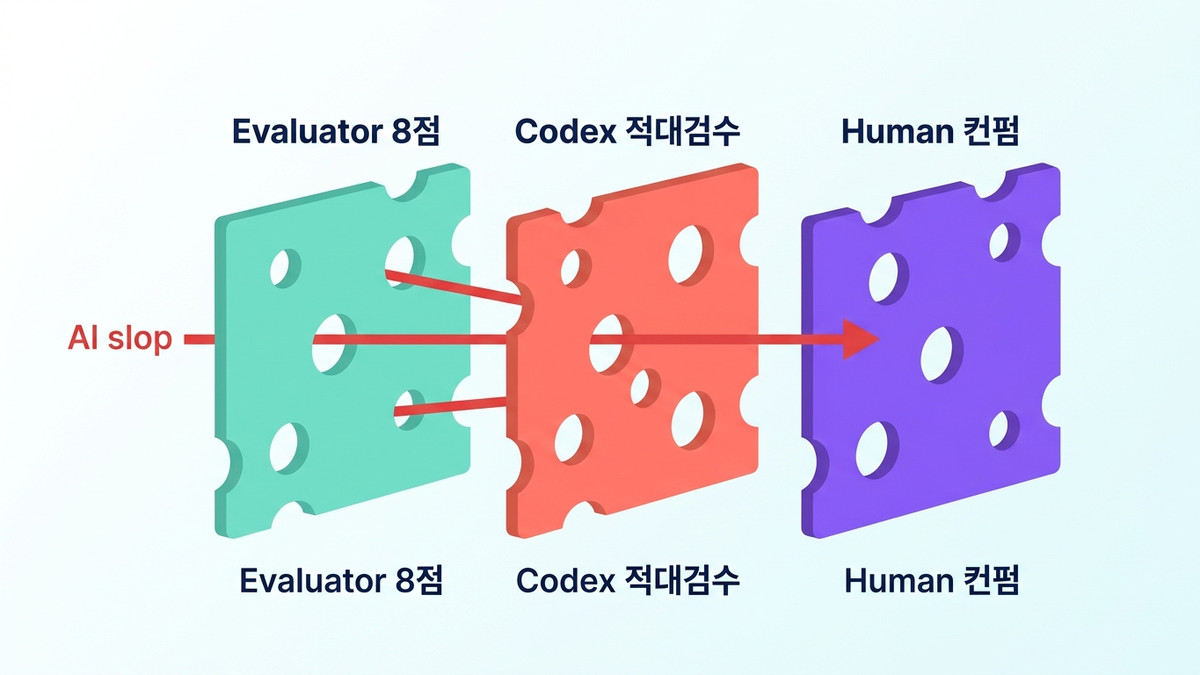
2. 컨펌 게이트는 치즈 슬라이스처럼 겹쳐야 한다 파이프라인 중 세 지점에서 사용자가 끼어든다: - Step 4 (Evaluator): AI가 8점 미만 판정하면 자동 반려 - Step 5 (Codex 독립검수): Claude가 쓴 걸 Codex(GPT-5.4)가 적대적 검수. "Claude = Generator, Codex = Independent Reviewer" 원칙으로 전환. 자체 생산물을 자체 리뷰하지 않는다. - Step 7.5 (발행 직전): 사람이 최종 컨펌. "보내기" 한 번만 하면 됨.
3. 발행은 "지금" 또는 "예약" — 사람이 시점을 정한다 처음에는 "글이 완성되면 Claude가 알아서 바로 올리게" 짰다가, 타이밍이 맞지 않아 버린 글이 몇 편 나왔다. 새벽에 발행돼서 유입이 끊기거나, X 피드가 비는 시간에 올라가거나. 그래서 발행 방식을 두 트랙으로 쪼갰다.
- "지금 발행" 트랙: 핫테이크/속보처럼 타이밍이 중요한 글은 완성 직후 내가 컨펌 → 즉시 발행. Blogger API로 바로 push.
- "예약 큐" 트랙: 에버그린 가이드·튜토리얼은
auto-publish/queue/폴더에 쌓아두고, 매일 19:00 GitHub Actions 크론이 큐에서 1건 pop해서 발행. 주말까지 채워두면 내가 여행 중이어도 꾸준히 돈다.
X와 네이버도 같은 원칙. X는 drafts/ 폴더에 쌓아두고 내가 수동 트리거 또는 예약 시간 지정, 네이버는 Chrome MCP가 브라우저에 초안을 띄워놓고 내가 검수 → 즉시 발행 또는 "임시저장"으로 예약. "AI가 알아서 시점을 정한다"만 막으면 사고가 거의 안 난다.
1개월 돌리고 깨진 것들 — 진짜 필드 리포트
실패 1: 완전 자동 모드 시도 → 즉시 슬롭
첫 3일은 "Claude가 알아서 발행까지" 모드로 돌렸다. 결과: 첫 편이 AdSense-friendly 템플릿 문구를 너무 흉내 낸 형태로 나왔다. 숫자도 틀렸고 톤도 교과서 같았다. 원복하고 Codex 독립검수 게이트 추가. 그 뒤로 점수 68점에서 반려된 글이 3편. 공개 유지본은 전부 다시 검수해 고쳤다. 내가 원하지 않는 내용, 내 경험에 대한 거짓말이 은근 섞여 들어가 있었다.
실패 2: X adapter가 블로그 톤 그대로 가져옴
처음엔 X에 블로그 첫 문단을 그대로 올렸다. 반응 0. 원인: 블로그는 "정보 검색" 맥락, X는 "피드 스크롤" 맥락이다. 첫 2-3문장에 훅이 없으면 그냥 지나간다. 어댑터를 고쳐서 X 전용 훅 문장 1개 + 본문 250자 + 셀프리플라이에 블로그 URL 구조로 바꿨다.
실패 3: 네이버는 API가 사실상 없다
네이버 공식 API는 카페·쇼핑 위주고, 블로그 글쓰기 API는 일반 개발자에게 닫혀있다. 2주 시도하다 포기하고 Chrome MCP 반자동 발행으로 전환. 브라우저 자동화로 초안을 띄워놓고, 내가 직접 검수 후 약간의 수정 후 마지막 "발행" 클릭만 사람이 한다. 네이버는 공개 발행 전 파일럿 단계 — 몇 차례 테스트 실행으로 절차를 다듬었고, AI 휴머나이징 체크리스트(26/27 기준) 통과 뒤 첫 공개 발행에 들어간다.
실패 4: 블로그 UI/UX 디자인을 30번도 넘게 고쳤다
콘텐츠 파이프라인이 돌아가기 시작하니 다음 문제가 보였다. 글은 좋은데 블로그에 들어오면 읽고 싶지가 않다. Blogger 기본 테마는 모바일에서 글꼴이 어정쩡했고, 상단 썸네일은 카톡으로 공유하면 잘려나갔고, 프로필 아바타는 어디에 붙여야 할지 감이 없었다.
이걸 풀려고 한 일이 30회가 넘는 디자인 반복이다.
- 1~5회차: 그냥 Blogger 테마 몇 개 갈아끼움. 결론: 기성 테마는 한국어 글꼴과 OG 썸네일 규격에 안 맞는다.
- 6~12회차: Contempo 기반 커스텀. 사이드바 absolute positioning이 모바일에서 깨지는 이슈. JS 폴리필 추가.
- 13~20회차: 딥리서치. "2026년 해외 테크 블로그 UX 트렌드", "Medium vs Substack vs 개인 블로그 가독성 비교", "카카오톡 공유 OG 이미지 크기/텍스트 가이드" 3개 주제를 Gemini + Codex + Claude로 교차검증. 결과를 한 파일로 묶고 거기서 규칙을 뽑음.
- 21~30회차: 뽑은 규칙을 실제 테마에 적용 → Chrome MCP로 모바일/데스크탑/카톡 미리보기 캡처 → Codex에게 "당신이 독자라면 어디서 이탈하겠나" 적대적 검수 → 반영 → 다시 검수. 개선/검수 무한 반복.
최종 룰 (지금도 계속 조정 중):
- 상단 썸네일 텍스트: 제목 90~110px 이상. 카톡이 OG 이미지를 23% 축소해서 렌더링해서 작으면 안 보인다.
- 이미지 스타일: 밝은 배경 기본, 다크 금지. 한국어 라벨 2~4자(최대 6개). 아바타 + 참조 로고(하이퍼리퀴드 글이면 HL 로고).
- 본문 구조: Editorial Warm + Top 1~3 cinematic 카드 + 4~5 리스트 + 프로필 sticky. Contempo absolute sidebar는 JS 폴리필 필수.
- 가독성: 문단 3~4줄 초과 금지, 굵은 글씨는 한 문단에 1~2곳만, 표는 모바일에서 가로 스크롤되게 overflow-x: auto.
이 한 덩어리 작업이 공유 CTR과 체류시간에 콘텐츠 자체보다 더 큰 영향을 줬다. "AI가 쓴 글"이라는 의심을 1차로 지우는 건 디자인이라는 걸 이때 배웠다.
실패 5: "품질" 점수만 보고 "재미"를 놓침
Evaluator가 SEO/정확성/구조는 잘 봤는데 읽는 맛을 놓쳤다. 그래서 4월 초에 "독자 수준 언어로, 전문용어는 괄호 해설" 규칙을 추가했고, 어미 다양화 규칙(~입니다/~이다/~인데/~더라/~거든요 혼용)을 Evaluator 룰에 박았다.
그러고도 여전히 글이 미끈미끈해서 한 단계를 더 추가했다. "내 경험이 반드시 본문에 녹게 하는 구조".
Evaluator 룰에 박은 체크리스트는 이렇다:
- 개인 에피소드 섹션 의무화 — 모든 글 본문의 30~50% 지점에 "내가 이걸 하다가 겪은 실제 사건" 문단이 있어야 통과. 없으면 8.0점 캡.
- 원천 인용 1개+ — 내 옵시디언 볼트의 실제 메모 / 실패 로그 / DeFi 거래 내역 / 쿠팡 폐업 회계 등에서 1개+ 인용. 인용하지 못하면 AI가 만든 픽션일 가능성 높음.
- 수치 앵커 3개+ — 이 글 기준 "약 20편", "30~50분", "35만원/월" 같이 내가 실제로 확인 가능한 숫자 3개+. 지어낸 숫자는 반려.
- 반증 가능한 한 문장 — "이건 내가 틀렸을 수도 있다"로 끝나는 한 문장. 이게 있으면 독자 경계심이 풀린다.
이 4개 체크를 통과한 글만 발행 큐에 들어간다. AI 슬롭 냄새가 나에게조차 나기 시작하면 내가 더 못 견딘다. 이 글의 훅 "자동화는 AI에게 명령만 잘하고 우회만 하면 대부분 해결된다" 부분도, 실제로 내가 지난 한 달 30번 이상 직접 말로 내뱉은 문장이다. 꾸며낸 게 아니다.

데이터 — 약 20편 돌리고 뭐가 달라졌나
발행량
- Blogger: 약 20편 (2026-03-24 ~ 2026-04-14, 초기 폐기본 제외한 공개 유지본 기준). 평균 평가점수 8.8/10, 이미지 평균 9.8장/편.
- X: 블로그 발행 시마다 롱폼 1트윗 + 셀프리플라이 자동 체이닝.
- Telegram: @wasajang 채널 RSS 푸시, 블로그 신규 글 100% 도달.
- Naver: 공개 발행 전 파일럿 단계. 설계·스킬·반자동 프로토콜 완성, 내부 테스트 실행 몇 차례 거친 상태.
시간
수동 발행 시절: 글 1편 + 4채널 배포 = 3~4시간. 지금: 아이디어 컨펌 + Evaluator/Codex 반려 대응 + 발행 직전 컨펌 = 30~50분. 자동화가 아니라 사람이 검수하는 시간만 남았다.
물론 이 30~50분도 여전히 사람 손이 많이 닿는 시간이다. Evaluator가 반려하면 그 이유를 읽고 내가 판단해야 하고, Codex 적대적 검수가 "이 문장은 근거 약함"이라고 까면 나도 다시 생각해야 한다. 완전 자동이 목표였다면 여기서 멈출 일이지만, 나는 이 30~50분이 글의 품질을 지키는 마지막 방어선이라고 본다. 그래서 당분간은 이 시간을 유지하면서, 반려 패턴이 반복되는 부분만 스킬에 규칙으로 박아 서서히 줄여나갈 계획이다. 예를 들어 "어미 다양화" 규칙은 원래 내가 매번 손으로 고치던 건데, 이젠 Evaluator가 자동으로 잡는다. 이런 식으로 한 달에 하나씩 룰을 늘리면 6개월 뒤에는 30~50분이 15~20분으로 줄어있을 거다.
수익
블로거는 AdSense 신청 준비 중 (기준: 발행 수 + 색인 + 저품질 0건). 블로그 직접 수익은 아직 0원이다. "수익 올렸다" 훅이 없는 게 오히려 솔직해서 나쁘지 않다고 본다.
유튜브는 수익 창출 요건을 넘어 시작됐고, 미미한 수익이 쌓이는 중이다. 문제는 이 시스템 자체가 상품이 없는 상태라는 점이다. 지금은 나 혼자 쓰려고 만든 자동화 파이프라인인데, 돌리다 보니 이 자동화 시스템 자체가 언젠가 내 무기이자 상품이 될 수도 있겠다는 막연한 감은 생겼다. 다만 지금은 "팔 수 있는 형태"로는 전혀 안 다듬어져 있고, 우선은 내가 먼저 충분히 써서 구멍을 다 찾는 게 맞다고 본다.
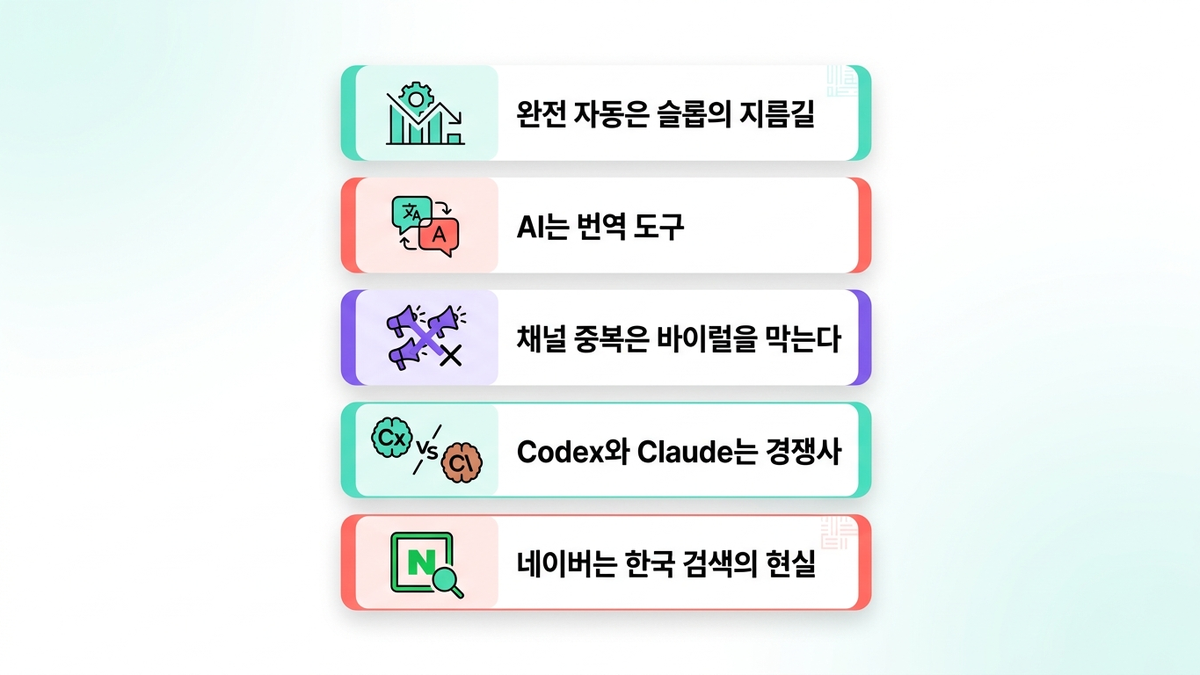
그래서 배운 것 — 5가지
- 완전 자동은 슬롭의 지름길이다. 3중 컨펌(Evaluator → Codex 적대적 검수 → 사람)이 타협할 수 없는 최소선.
- AI는 생각하는 게 아니라 번역하는 도구다. 원본 생각은 볼트에서, AI는 4채널로 번역.
- 채널 간 중복은 바이럴을 막는다. 어댑터 1개당 1개 포맷, 같은 문단 복붙 금지.
- Codex와 Claude는 경쟁사다. 그 긴장을 시너지로 쓴다. Claude가 쓴 걸 Claude가 리뷰하면 자기 편. Codex(다른 회사의 다른 모델)에게 적대적 검수를 맡기면 Claude가 덮어준 약점이 잡혀나온다. 경쟁사의 모델일수록 서로를 안 봐준다.
- 네이버는 한국 검색의 현실이다. API가 안 되니 반자동이라도 붙여야 한다. AI 검색이 늘어나고 있긴 하지만, 여전히 한국 독자에게 나를 노출하고 브랜딩하는 창구로서 네이버는 가장 강력한 플랫폼 중 하나다. 무시할 수 없다.
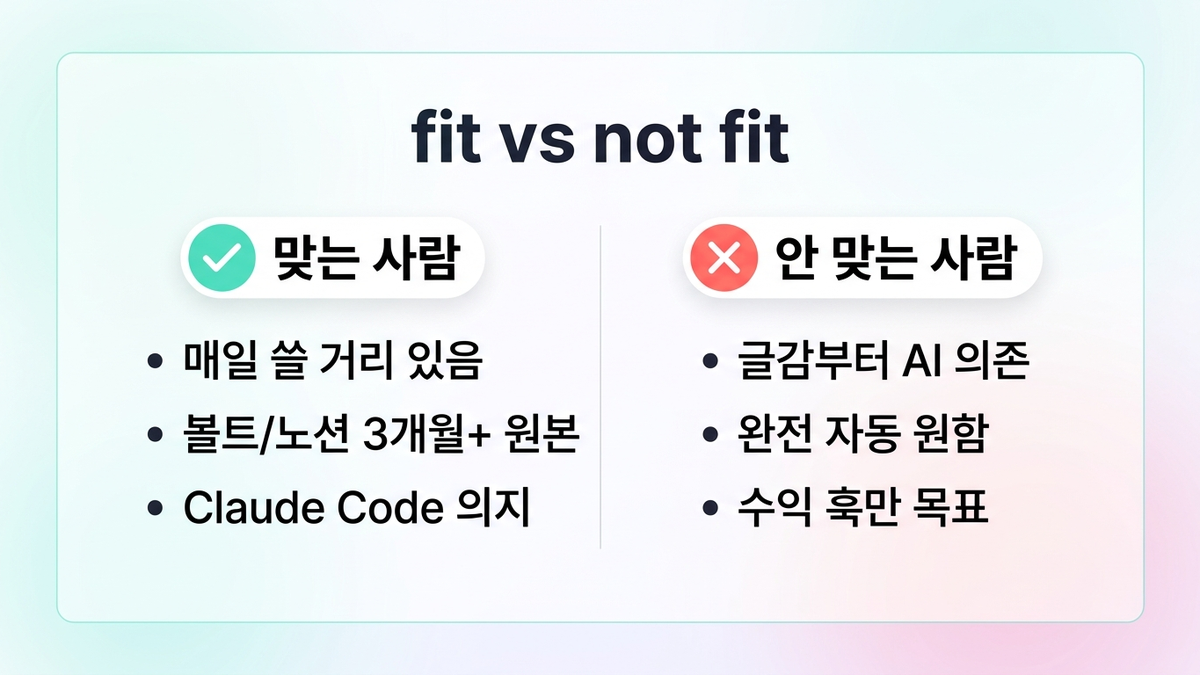
누구에게 맞는 시스템인가 (솔직 버전)
- 맞음: 이미 매일 쓸 거리가 있는 사람. 볼트/노션/에버노트에 3개월+ 쌓인 원본이 있는 사람. 코딩 조금 가능하거나 Claude Code 쓸 의지 있는 사람.
- 안 맞음: 글감부터 AI에게 기대는 사람. "월 100만원 수익" 훅이 목표인 사람. 완전 자동을 원하는 사람.
솔직히 AI OSMU로 0원에서 월 500만원 같은 훅은 지금 시장에서 거짓말에 가깝다. 슬롭 탐지는 계속 정교해지고, Google도 AI 사용 자체보다 대량·저품질·원본성 없는 콘텐츠를 문제 삼는다. 살아남는 각도는 "사람이 원본, AI는 번역" 하나뿐이다.
다음 단계
- 이번 주: 네이버 파일럿 1편 (이 글의 축약본 + HIP-4 주제 글). Chrome MCP 반자동 발행 프로토콜 실제 검증.
- 5월: 쓰레드(Threads) + 인스타그램 카드뉴스 어댑터 추가. 4채널에서 6채널로. 인스타 카드뉴스는 블로그 핵심 3~5포인트를 정방형 1200x1200 이미지 슬라이드로 변환하는 어댑터. 쓰레드는 X와 비슷하지만 알고리즘 특성상 첫 3줄이 다름.
- 6~7월: 쇼츠 영상 파이프라인 구축. 블로그 글 → 대본 → 음성 합성 → 영상 조립까지. 이건 단순 OSMU 확장이 아니라 자체 수익 채널 + 내 영상 편집/기획 노하우를 쌓는 과정. "mass gen 쇼츠"가 아니라 "내 글에서만 뽑아낸 쇼츠"를 어떻게 짤지가 과제.
그리고 이 시스템은 오픈소스로 공개할 예정이 없다. 이유가 철학적인 건 아니다. 솔직히 말하면 세 가지다.
- 겁이 난다. 아직 오픈소스로 뭔가를 공개해본 적이 없고, 공유 문화 자체를 잘 이해하지 못하고 있는 것 같다.
- 이게 최선이라고 생각한다. 아이디어에 동의하면 직접 구축하는 게 가장 좋다는 게 아직까지 내 생각이다. 코딩을 정식으로 배우지 않은 바이브코더라 그런 편견이 있을 수 있다.
- 악성 코드가 무섭다. 온라인에서 다운받는 플러그인/스킬에 그렇게 많은 악성 코드가 숨어있다는 얘기를 듣고 나니, 내가 공유한 걸 누군가가 똑같이 의심할 것 같아서 자신이 없다.
그리고 무엇보다, 나는 코드가 아니라 내 경험을 번역한다. 다른 사람이 스킬을 그대로 복제해도 원본 볼트가 다르니 시작점이 달라진다. 이게 역설적으로 내 해자(moat)라고 본다.
자주 받는 질문
Q1. 왜 n8n / Make / Zapier가 아니고 Claude Code + Python인가?
나도 2025년에는 make.com / Zapier로 무언가를 구축하려고 했었다. 노코드 블록을 연결하는 방식은 시작하기는 쉬운데, 한국어 어미 규칙이나 "이 주제는 내 쿠팡 폐업 맥락을 섞어서 쓰라" 같은 세밀한 룰을 넣으려고 하면 블록 하나에 JSON이 20줄씩 들어가기 시작했다. 결국 "노코드"가 아니라 GUI 위의 코드였다.
그러다 2025년 후반~2026년 초에 OpenCloud(내가 쓰는 Claude Code 하네스 별명)와 Claude Code가 본격적으로 열리면서, 자연어로 워크플로우를 짜고 스킬 단위로 버전 관리하는 세상이 훨씬 매력적이었다. "이 글 쓸 때는 내 볼트의 이 폴더를 먼저 읽고, 숫자는 반드시 발행-로그에서 가져와" 같은 규칙을 마크다운 SKILL.md 한 파일에 적어두면 Claude가 그대로 따른다. 이게 make.com 블록보다 훨씬 편했다.
결정적인 건 디버깅이다. make.com에서는 시나리오가 망가지면 블록 하나하나를 열어봐야 하는데, Claude Code는 그냥 "이 단계에서 왜 이렇게 됐어?"라고 물어보면 대화로 원인을 찾아준다. 코딩 모르는 바이브코더한테는 이 한 기능이 다른 모든 차이를 덮었다.
Q2. 비용이 얼마나 드나?
현재 기준 (월): - Claude Max = ~30만원 - Gemini Pro 구독 = 2.7만원 (한국 요금) - Codex (Plus 구독) = 2.7만원 - GitHub Actions / Blogger / Chrome MCP = 무료 - miniPC 전력비 = ~5,000원
약 35만원/월. 블로그 AdSense + 쿠팡 파트너스 + 추후 뉴스레터로 상쇄 목표.
Q3. 완전 초보는 따라할 수 있나?
지금 당장은 아니다. 최소한 Claude Code CLI 개념은 있어야 한다. 단, Claude Code + 바이브코딩은 6개월 전보다 훨씬 진입장벽이 낮아졌다. AI로 무언갈 해보겠다는 집념과 재미만 느낄 수 있다면 이만큼 한다는 게 증거.
Q4. 이 글 자체도 AI가 썼나?
Nucleus(주장·숫자·구조)는 내가 썼고, 초안 확장과 이미지 위치는 AI가 짰다. 그다음 Codex가 적대적 검수를 했고, 최종 편집은 다시 사람 손을 거쳤다. 이게 지금 내 OSMU 시스템의 기본 흐름이다.
💬 더 많은 인사이트 받기
이 블로그의 새 글과 실시간 크립토/AI 인사이트를 받아보고 싶으시다면:
🐦 X (@coindowoomi) — 실시간 인사이트
📨 텔레그램 (@wasajang) — 블로그 새 글 푸시 알림
💬 카카오톡 오픈채팅 — 더 즉각적인 소통
🟢 네이버 블로그 — 코인 스토리 아카이브
🔗 관련 심층 가이드
- AI 에이전트 자동화 완전 가이드 2026 — S등급 Pillar. 멀티 에이전트 오케스트레이션의 전체 그림.
- Claude vs GPT vs Gemini 실전 테스트 — 왜 오케스트레이터는 Claude, 리뷰어는 Codex, 장문 분석은 Gemini인지.
- Obsidian + Claude 세컨드브레인 실전 셋업 — 원소스가 볼트여야 하는 이유.
이 글은 2026년 4월 15일, 블로거 약 20편 발행 시점의 현장 리포트입니다. 시스템은 매주 개선되고 있고, 다음 월간 리포트에서 달라진 점을 다시 기록합니다.


댓글
댓글 쓰기